Deloitte's AI Hallucination Problem
What went wrong and how to prevent it with proper agentic design

What went wrong and how to prevent it with proper agentic design
You've probably seen the Deloitte story by now. Their report had completely fabricated references, obviously generated by an LLM. And honestly, it's not just them. We're seeing this pattern everywhere. Companies rushing to deploy AI, getting burned, and then wondering if the technology is even ready.
Here's the thing though: the technology is fine. The implementations are garbage.
I've spent the last two years working with manufacturers, consulting firms, and enterprise clients building AI systems that actually work at scale. The difference between systems that hallucinate nonsense and systems that deliver real value isn't the model you're using. It's whether you understand agentic design.
Look, you can spin up a RAG system in an afternoon. You can have an agent running in a day. But getting outputs you'd actually put your name on? That takes real architectural thinking.
The Deloitte incident is a perfect example. They were using Azure OpenAI, which has guardrails built in specifically to prevent this kind of thing. So what went wrong? No training. No process. No understanding of how to actually structure these workflows when you're working at scale.
And it's not just consulting firms. I see this everywhere. Teams that treat LLMs like magic boxes where you dump a prompt in one end and trust whatever comes out the other.
This sounds obvious but almost nobody does it: structure your agents the same way you'd approach the work yourself.
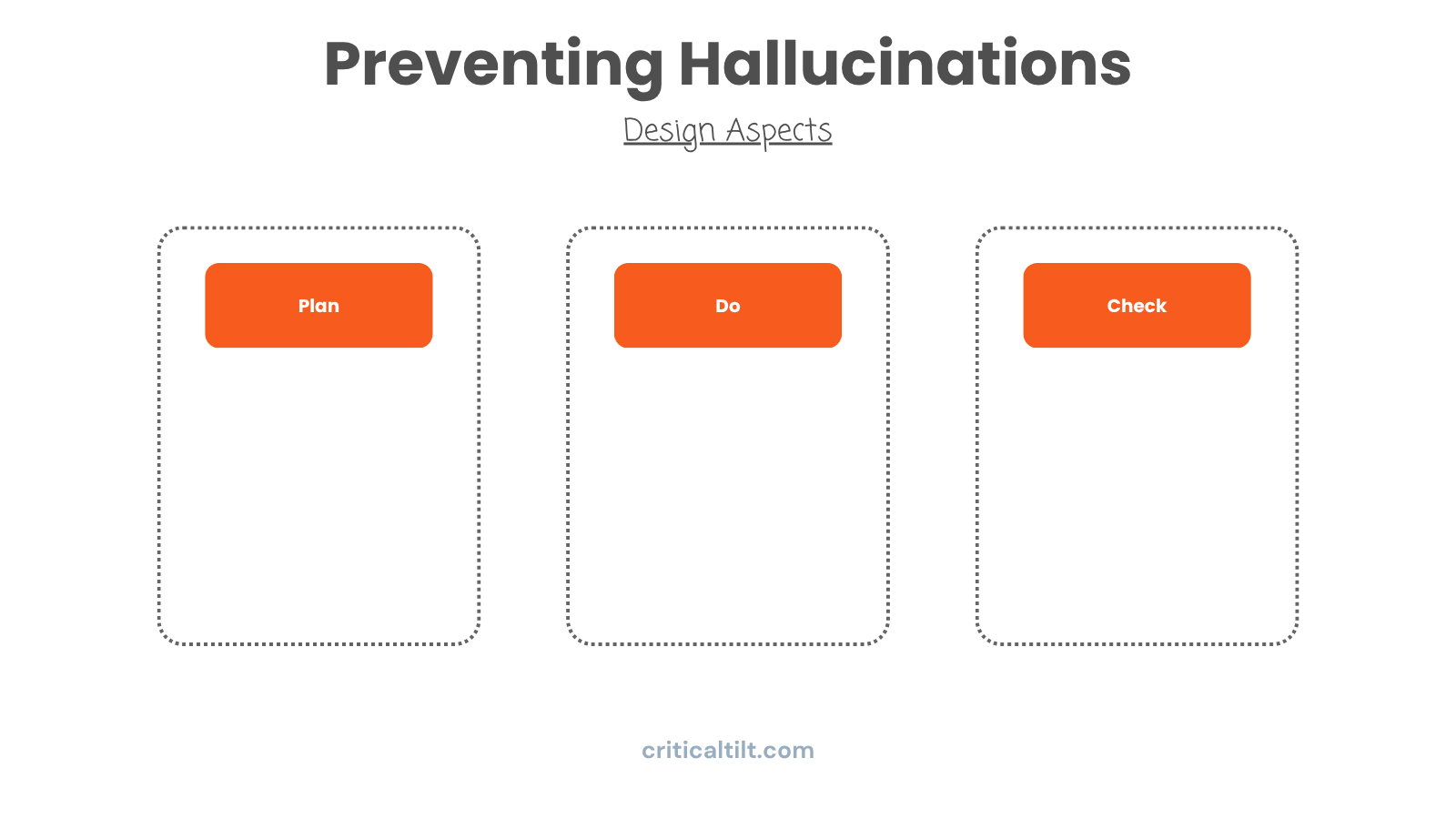
When you write an important email, you don't just start typing and hit send. You think about what you want to say, you write it, then you read it over before sending. Maybe you check that the numbers are right or that the tone matches what you're going for.
Your AI workflows need that same structure. Plan, do, check. Every time.
Planning means figuring out your approach, what you'll need, how you'll structure things. Doing is the actual execution. Checking is where you verify the output isn't hallucinating, didn't drift off topic, and actually matches what you needed.
And here's where it gets interesting. You can nest this structure. Your planning phase might have its own internal plan-do-check cycle. Like, outline a general approach, have another agent poke holes in it, then move forward with the refined version. Each layer cuts down on the chances of things going sideways.
The biggest mistake I see? Megaprompts trying to do research, analysis, writing, fact-checking, and formatting all at once.
It doesn't work. LLMs are terrible multitaskers. They're actually really good specialists.
Instead of one massive prompt, break it down. Research agent finds and pulls information from verified sources. Structure agent builds the outline and framework. Detail agent inserts specific facts and evidence. Verification agent checks accuracy and catches hallucinations. Polish agent handles tone and readability.
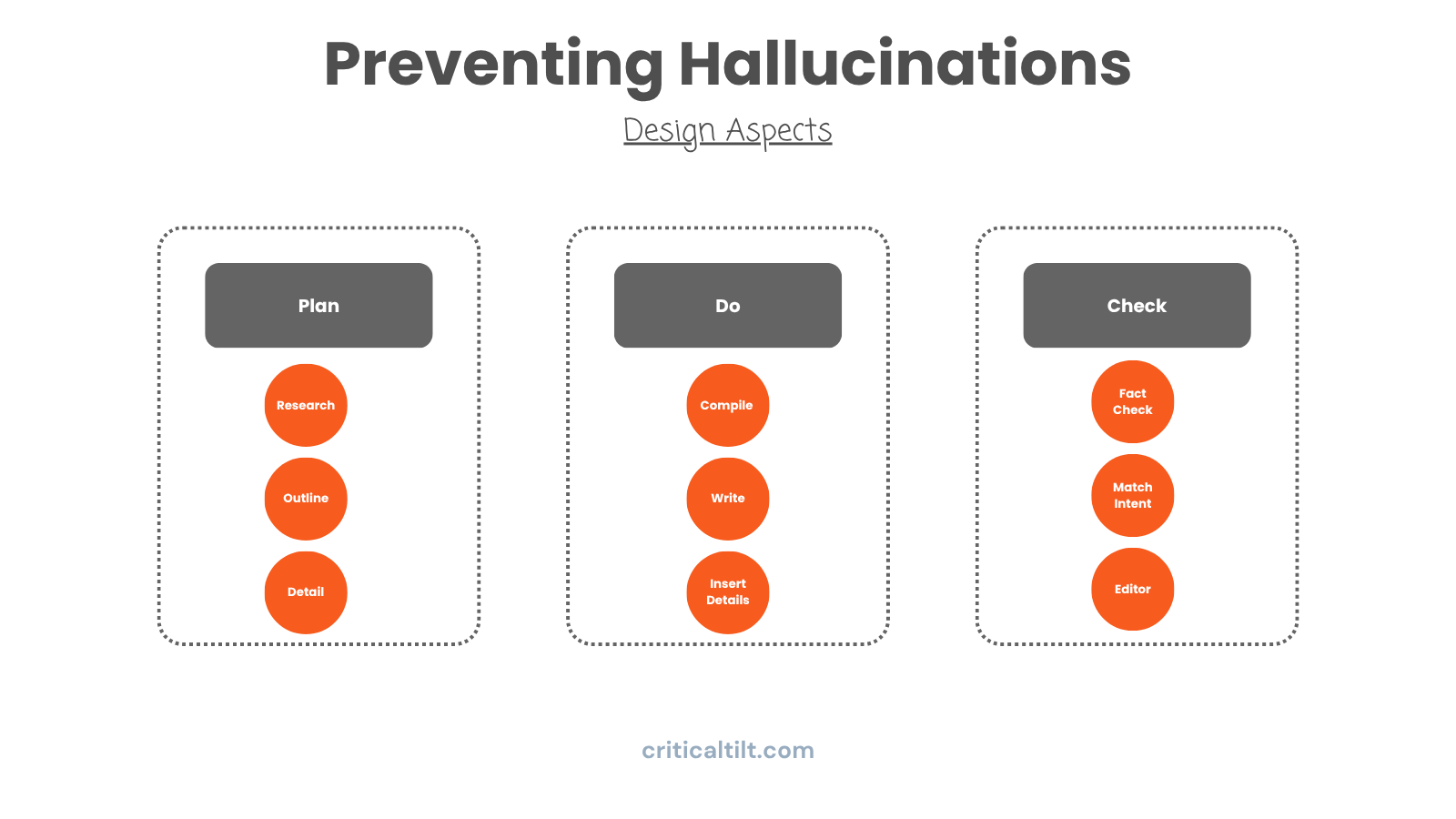
When each agent has one job, you can tune it, test it, and actually get consistent results. Plus when something breaks, you know exactly where to look.
This one's subtle but it makes a huge difference.
If you tell an LLM to write a complete document in one shot, it's going to run into situations where it needs a fact right now. And if it doesn't have that fact, it'll just make one up. That's where hallucinations come from. The model feeling pressure to fill gaps on the fly.
Better approach: split it into two passes.
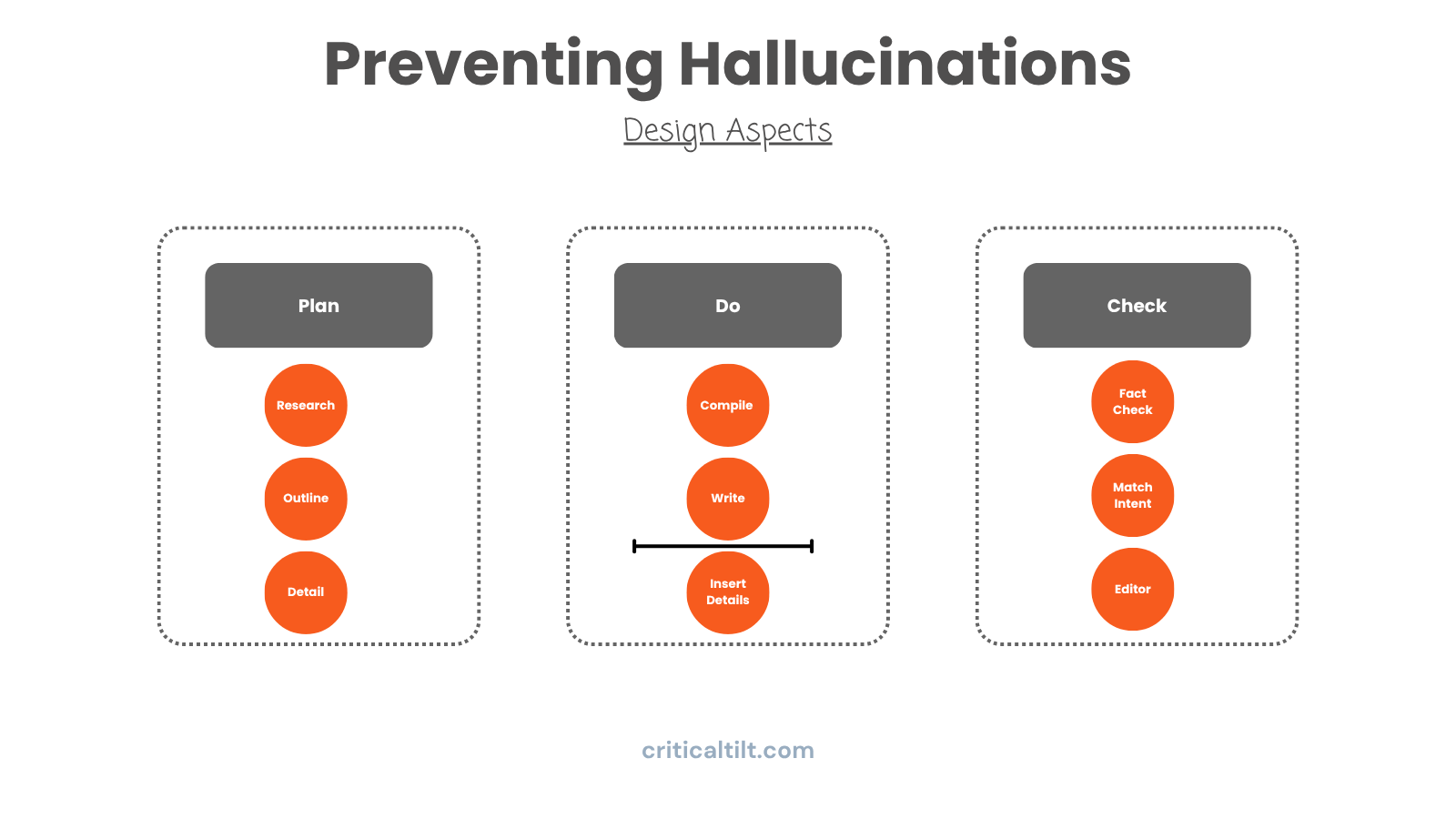
First pass: have an agent write the general argument and structure without worrying about specific facts yet. Just the logic and flow.
Second pass: different agent goes through and inserts the actual data, citations, and details. This agent is only pulling from verified sources (your research database, web searches, whatever you've set up).
Why does this work? You've changed where the information comes from. The structure is coming from reasoning. The details are coming from real sources. No pressure to fabricate anything.
Grounding documents are probably the most underutilized tool we have.
Think of it like giving the AI your company's playbook. For our manufacturing clients, we feed agents the actual process docs and quality standards. For consulting firms, it's methodology frameworks and how they approach problem-solving.
When the agent hits a decision point, it's not just pulling from general training data. It's referencing your specific documents to make sure it solves problems the way you solve problems, extracts the info you care about, writes in the tone you use.
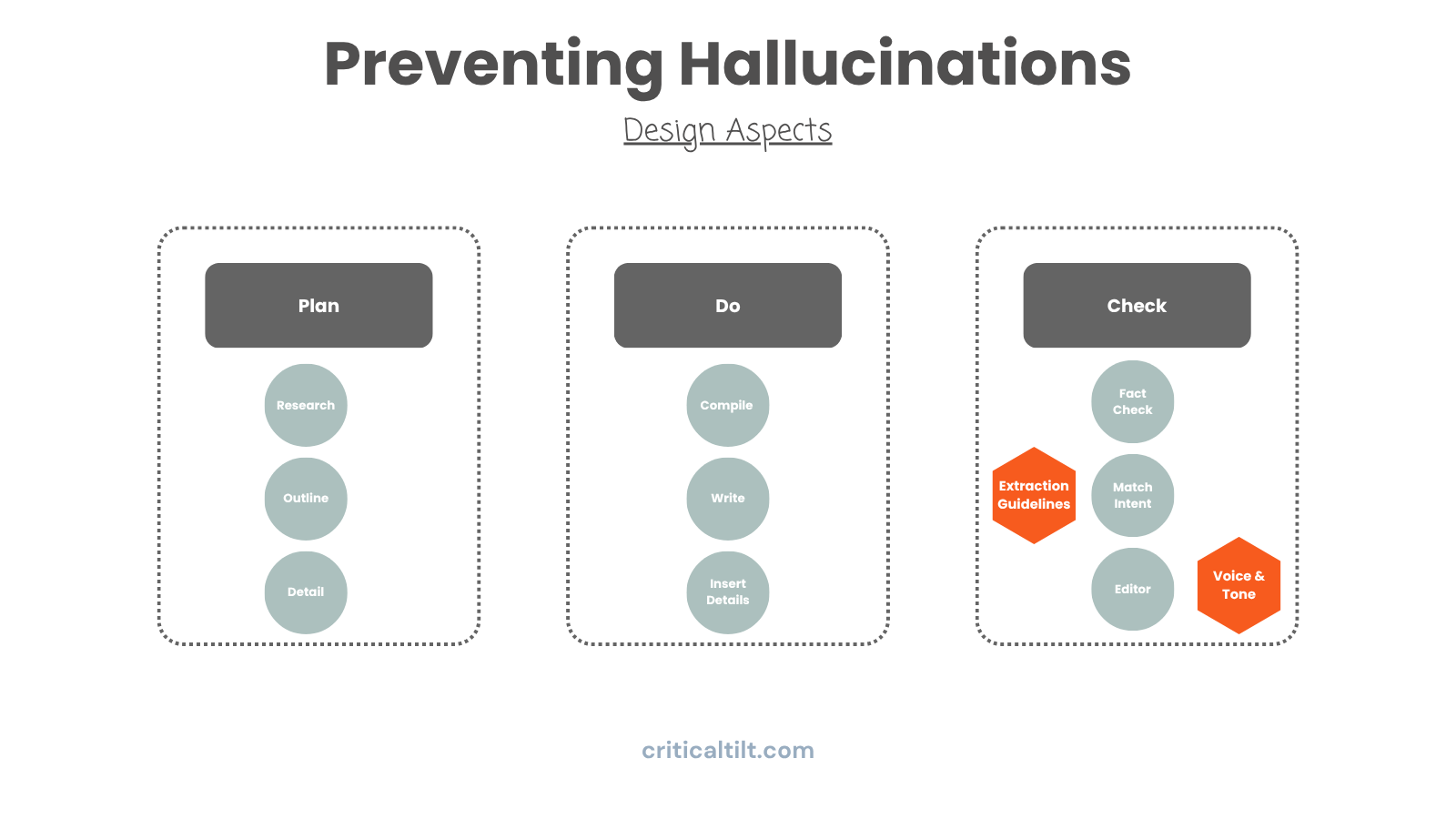
A government contractor analyzing an SOW cares about completely different things than a consultant looking at the same document. One's focused on compliance and security requirements. The other's looking for ROI and efficiency gains. Grounding makes sure your AI knows which lens it should be using.
Most direct way to stop hallucinations? Don't let the AI make stuff up from memory.
When an LLM generates content from what it knows (its latent space), it'll fill gaps by creating plausible-sounding facts. But if you force it to pull from specific sources, you've massively reduced the surface area for fabrication.
Some ways to do this:
Make it search the web instead of "remembering." Tools like Tavily work well for this. Pull data from your actual databases instead of estimates. Reference historical projects that are documented. Connect to external APIs for authoritative data.
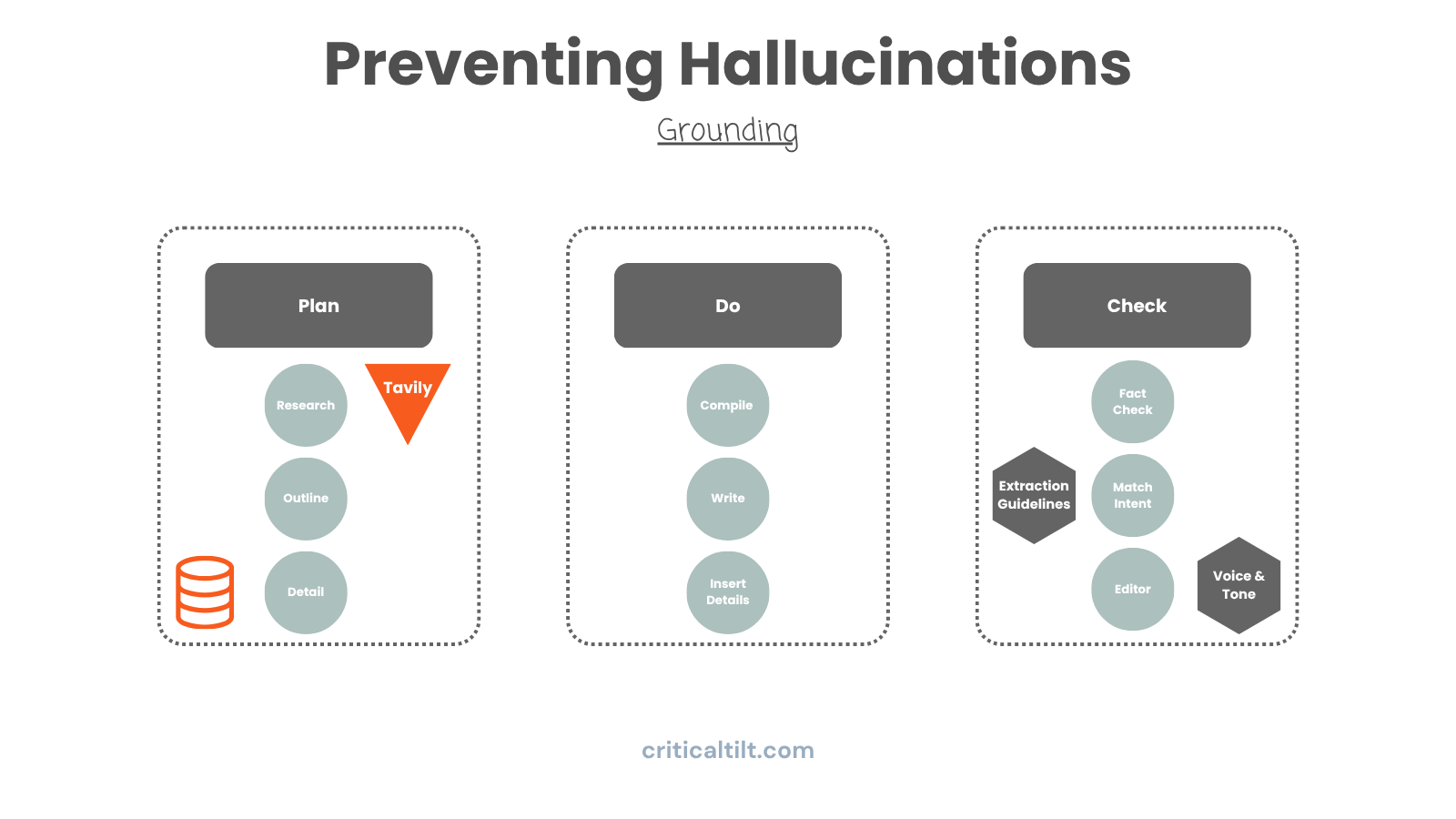
Does this eliminate all risk? No, the internet itself has plenty of misinformation. But you've shifted the AI from creative synthesis mode to verified retrieval mode. Big difference.
Here's a problem that shows up in longer workflows: drift.
Your planning agent sets clear objectives at the start. But six or seven agents later, those original goals feel pretty distant. The system starts making decisions based on what just happened instead of what you actually needed.
When drift happens, the LLM fills that gap with confabulation. It invents justifications for decisions that don't line up with your original intent anymore.
Solution is an orchestration layer. Basically a supervisor agent that holds onto the original plan and checks periodically whether everyone's still on track. If things have drifted, it can trigger loops to revise work and pull things back into alignment.
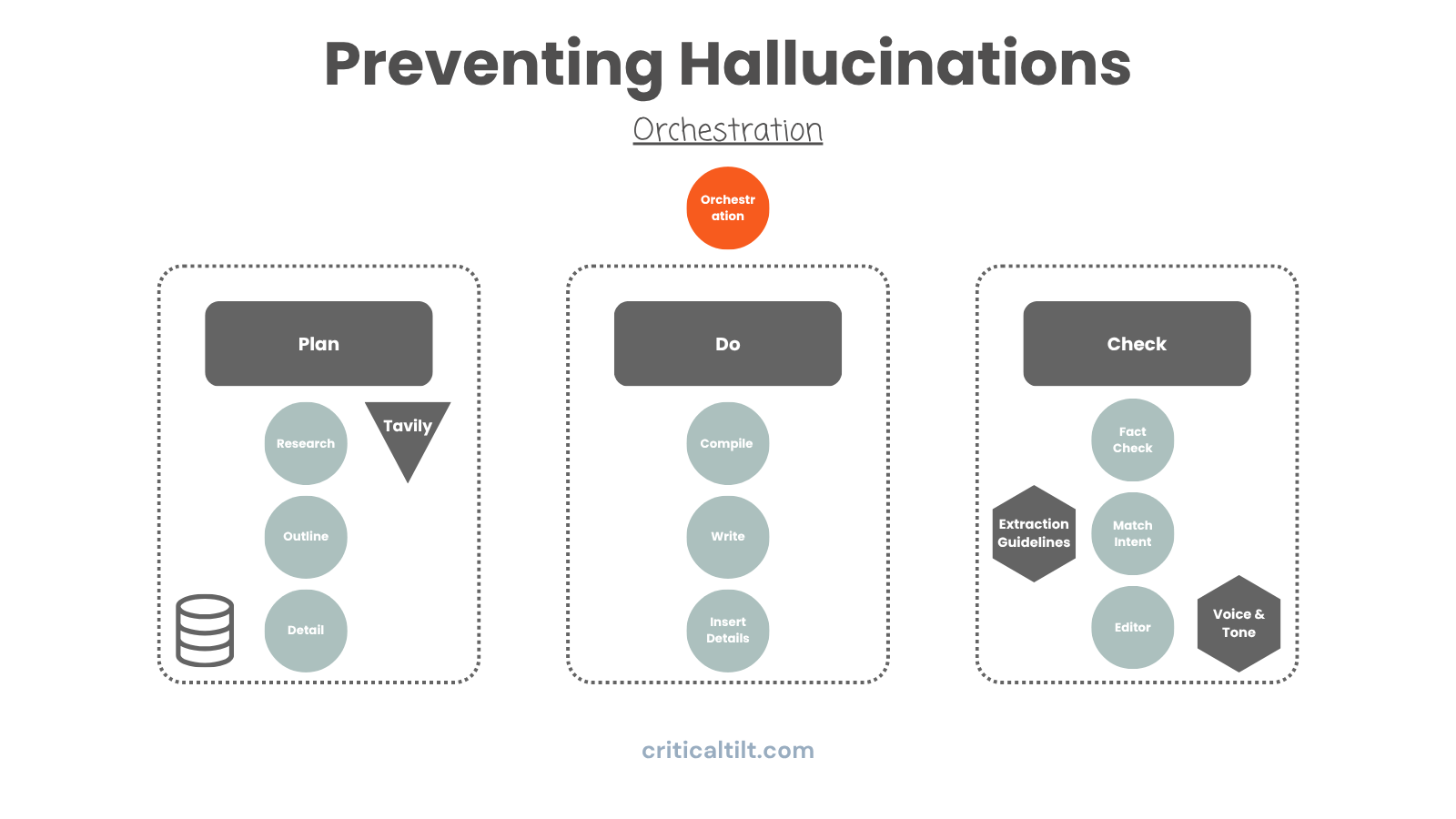
Think of it like a project manager who keeps asking "wait, are we still solving the original problem here? Does this actually match what we said we'd deliver?"
This one doesn't get used enough: have different models generate and verify content.
If GPT-4 writes something and GPT-4 checks it, they've got the same blind spots. Same training data, same biases, same latent space where hallucinations come from.
But if GPT-4 generates content and Claude verifies it? Now you've got productive tension. Different training, different approach, catches things the first model missed.
You could have GPT-4 generate a research summary, Claude check the citations, maybe a smaller fine-tuned model do a final fact-verification pass.
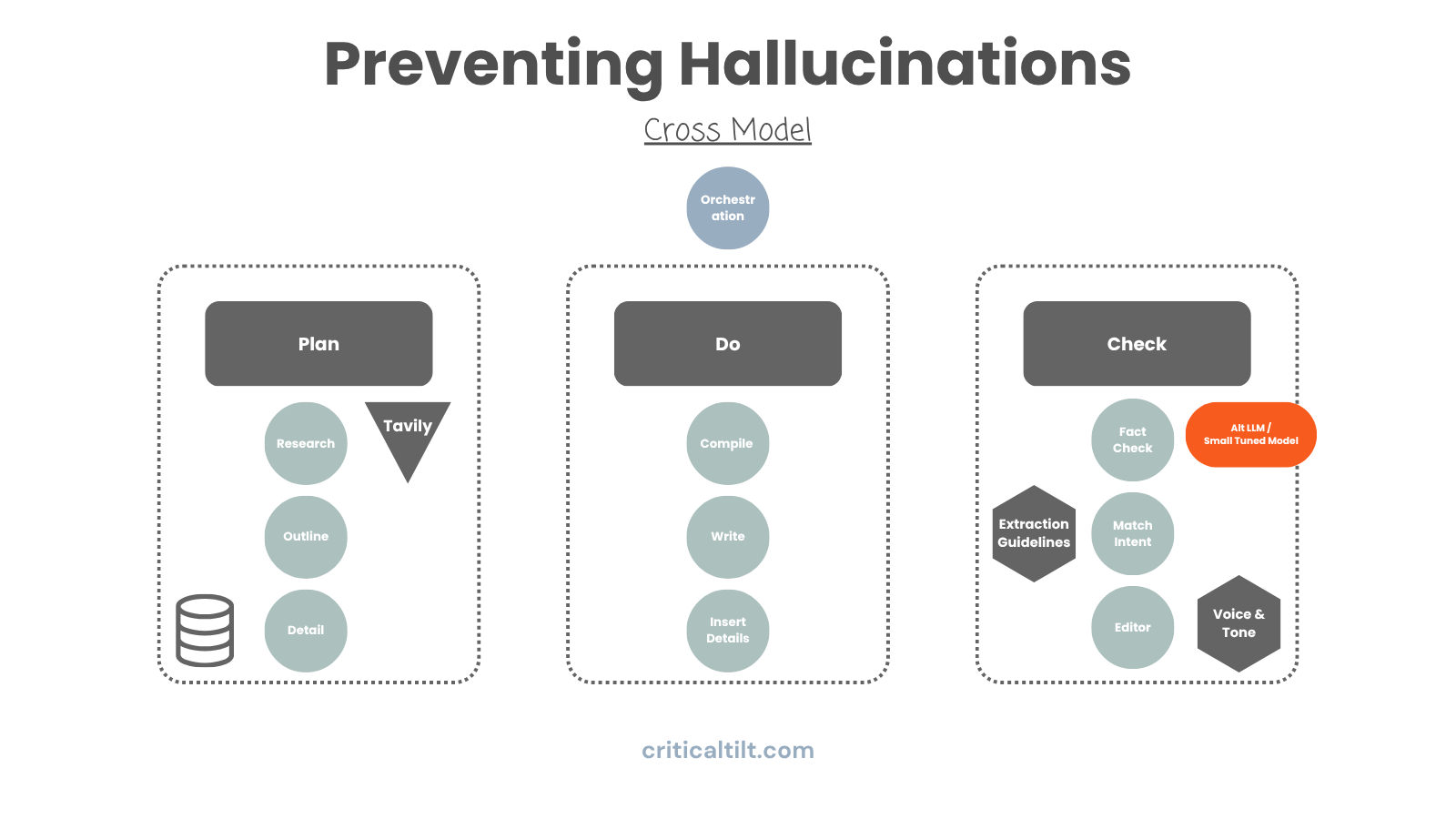
It's the same principle as financial controls where one person writes checks and someone else approves them. The redundancy catches errors that slip through single-layer review.
Even better if you can swing it - train small specialized models for specific verification tasks. These can get really good at spotting fabricated citations or logical holes.
Even with good architecture, your individual prompts matter.
Give the AI permission to say "I don't know." Sounds basic but most systems are trained to always provide an answer. That's how you get confident hallucinations. Explicitly tell it that it's okay to skip citations it can't verify or suggest alternatives when it's uncertain.
Make it show its work. Don't just ask for an answer, require the reasoning and evidence. Two benefits: you can verify the logic, and you've got an audit trail. For our manufacturing clients doing demand planning, we want to know why it ordered 100 units of a part. If the reasoning is "I didn't know what to do," we can catch that and loop it back for a better answer.
Add confidence scores. Have the agent rate how confident it is in specific claims. Then you can filter (only let facts above 85% confidence through, or cycle back anything that's low/medium confidence for additional verification).
Don't wait until the end to check quality. Verify as you go.
Your workflow is basically a graph. Nodes where agents do work, edges where output moves between them. At each edge, insert a check. Critics evaluate quality. Adversaries try to find problems. Filters apply threshold tests.
If verification fails, loop back to the previous node and have it try again. Only let output move forward when it passes your exit criteria.
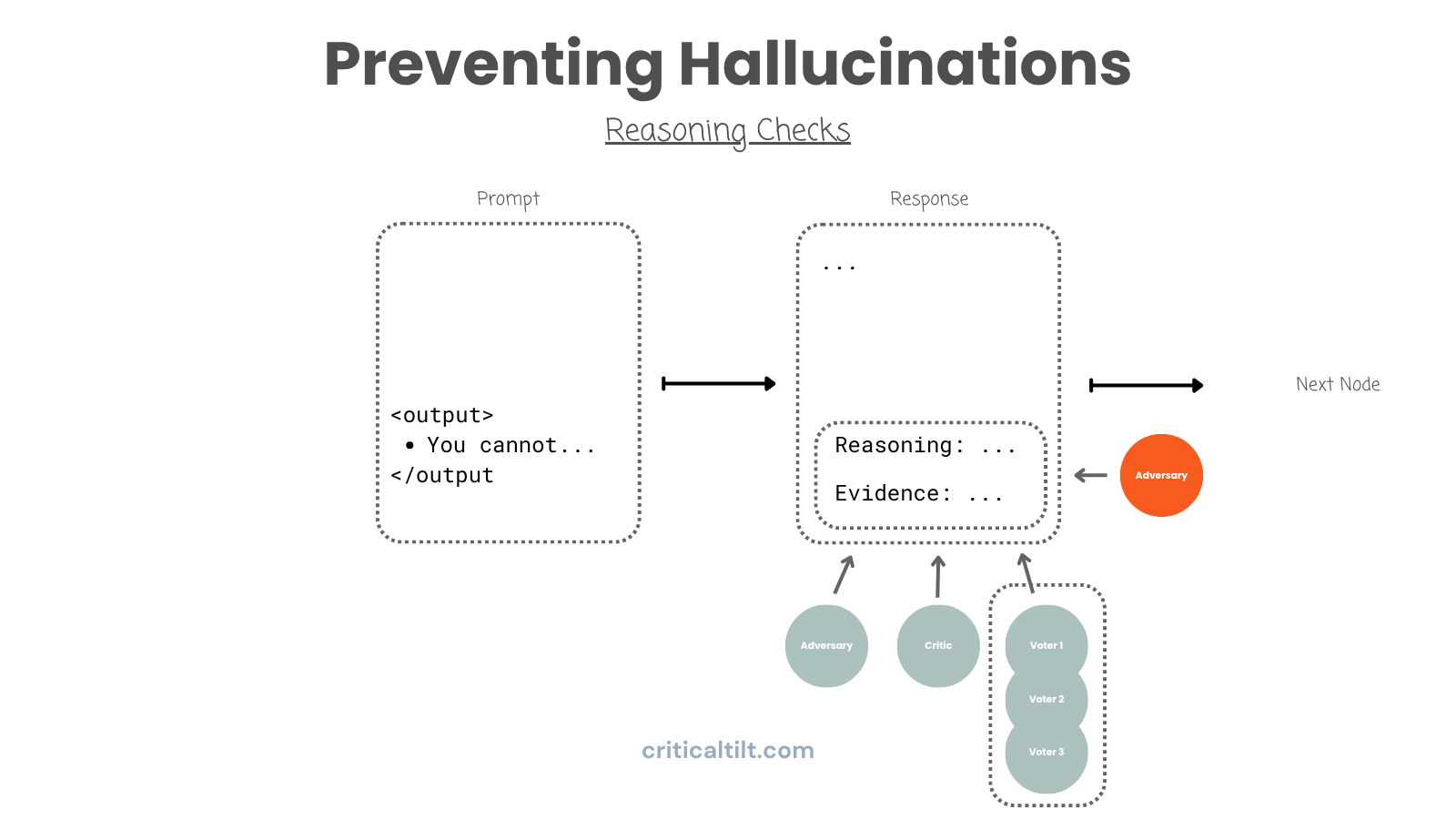
Example for a consulting proposal: Agent drafts responses to RFP requirements. Critic checks whether responses actually address what was asked. Adversary identifies weak arguments or missing evidence. Compliance filter makes sure you haven't made claims you can't support.
Work only proceeds when all checks pass. Yeah, it's slower than just generating everything in one shot. But you're not going to end up like Deloitte with fake citations in a client deliverable.
This is powerful but most people skip it.
Input schemas define exactly what goes into each agent and in what format. Prevents messy data from causing confusion. Also gives you some protection against prompt injection, though that's a whole separate security conversation.
Output schemas structure responses so you can verify them piece by piece. Instead of one giant document, structure output as JSON with separate fields for content, evidence, citations, reasoning, confidence scores.
Why does this matter? Because now you can check each piece independently.
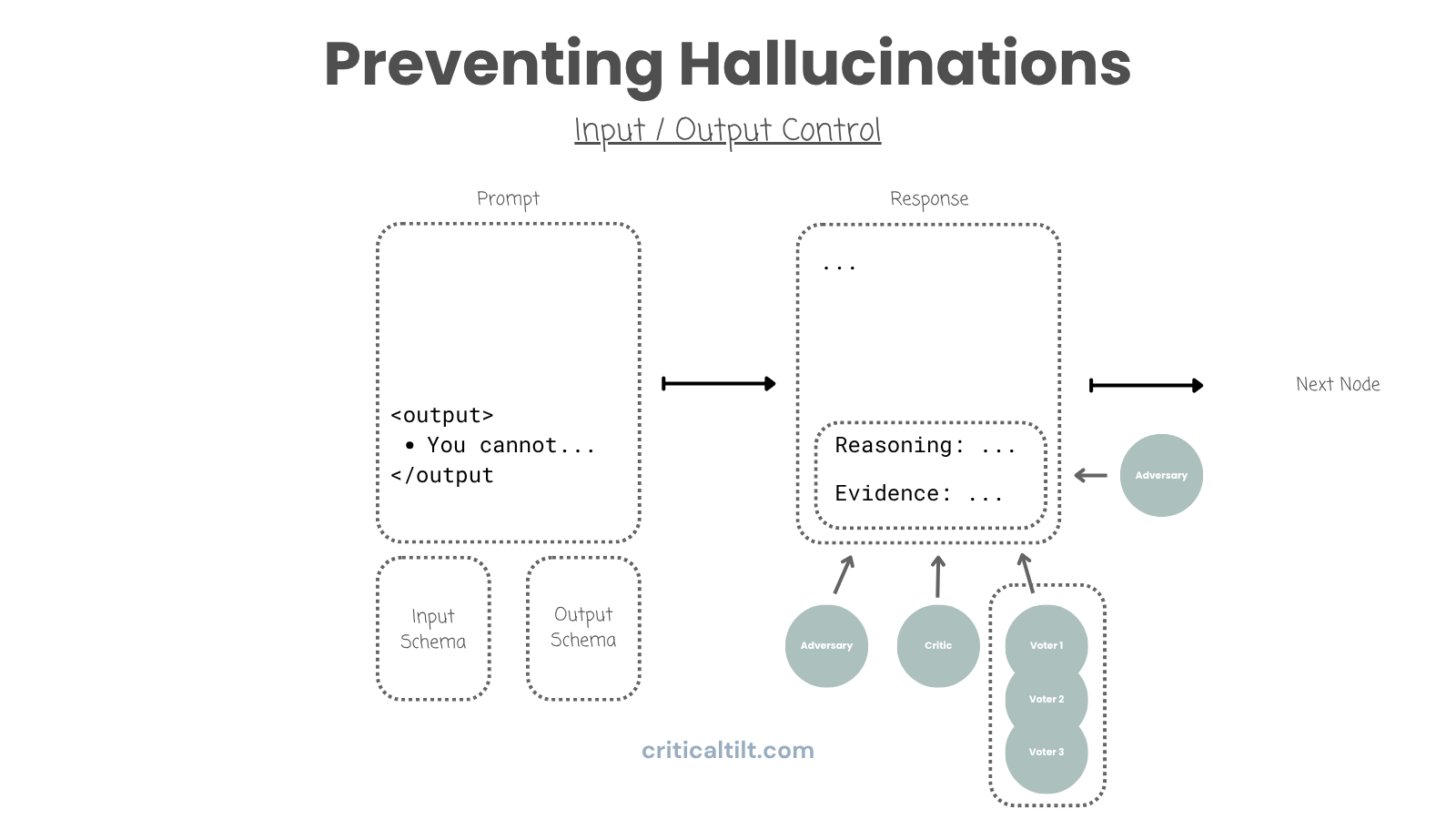
Say you've got a 50-page document. Sending the whole thing to a fact-checker dilutes the context and you'll miss stuff. But if citations are in their own field, you can extract just those and verify each one individually. Same with headlines, evidence, reasoning. Pull out exactly what you need to check and nothing else.
We use this constantly for editing workflows too. Extract all the headlines and refine them. Pull evidence citations and verify they're current. Check reasoning against logic standards. Way more effective than trying to do everything at once.
Most teams skip this completely. Don't be like most teams.
You need evals at two points:
Before you build anything, document what inputs you'll get, what outputs you need, what success looks like, what edge cases might break things. This exercise forces you to think through the design patterns you'll need before you've written any code.
After you deploy, continuously test against a comprehensive suite. Run production scenarios through your pipeline. Collect responses from verification agents. Track where adversarial checks are failing. Monitor confidence scores and reasoning quality.
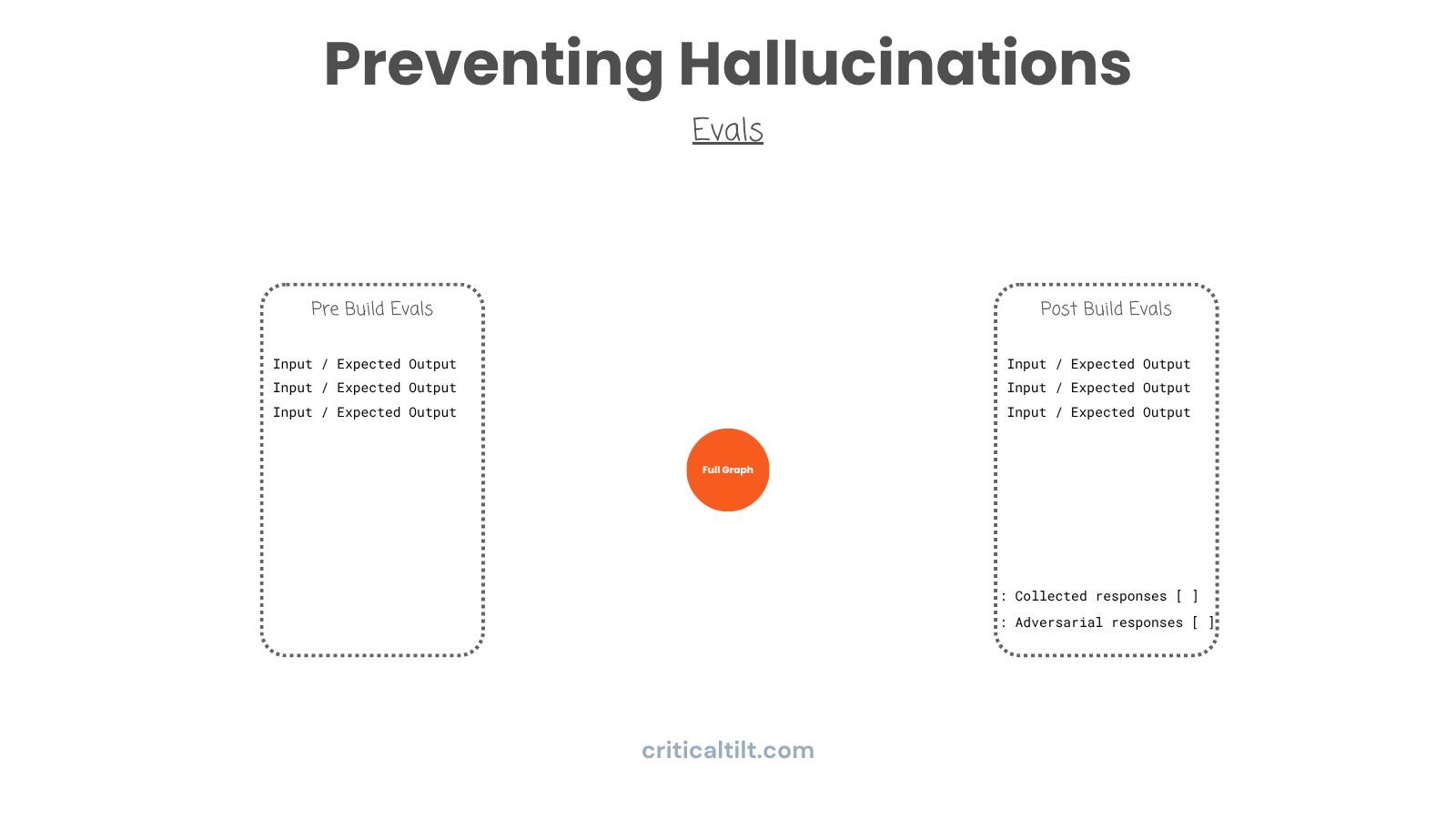
Watch for drift. Models change with updates. Your own system drifts as you modify prompts. Continuous eval catches degradation before users see it.
And every time something breaks in production? Add that scenario to your test suite. Your eval set should grow based on real failures.
The gap between AI that works and AI that becomes a cautionary tale isn't the model. It's the architecture.
Companies getting real results at scale do these things: Structure workflows like humans would approach the work. Use specialized agents instead of trying to make one agent do everything. Control where data comes from and ground outputs in verified sources. Build verification into every step instead of hoping for the best at the end. Use multiple models to cross-check critical outputs. Structure data so they can verify specific pieces instead of entire documents. Actually run evals continuously instead of deploying and praying.
This isn't theoretical. We've built these patterns into manufacturing systems, consulting workflows, government contracting pipelines. They work when you do them right.
The models keep getting better. But the difference between companies that succeed with AI and companies that generate bad press keeps growing.
It's not about access to technology anymore. It's about whether you're willing to invest in proper design, training, and process discipline. The organizations that treat AI deployment as an architectural problem will pull ahead. The ones that keep throwing prompts at problems and hoping for magic will keep making headlines.
The tech is ready. Question is whether your implementation is.
AI hallucinations occur when LLMs are forced to fill knowledge gaps on the fly, generating plausible-sounding but fabricated content. The root cause is architectural — systems that lack verification steps, use single-pass generation, or rely on the model’s latent memory instead of verified sources create the conditions for hallucination.
Plan-Do-Check structures agentic workflows the way humans approach work — plan the approach, execute it, then verify the output. Each phase can contain its own nested cycles, with separate agents reviewing and poking holes in outputs before they move forward. This layered verification catches hallucinations before they reach the final deliverable.
LLMs perform better as specialists than multitaskers. A single megaprompt handling research, analysis, writing, and fact-checking produces inconsistent results. Breaking workflows into specialized agents — research, structure, detail, verification, polish — makes each step tunable, testable, and easier to debug when something goes wrong.
Grounding documents are company-specific references — process docs, methodology frameworks, quality standards — fed to AI agents at decision points. Instead of pulling from general training data, the agent references your actual playbook, ensuring outputs match your organization’s approach, terminology, and standards.
Using different LLM providers to generate and verify content creates productive tension. Models from different providers have different training data, biases, and blind spots. When one model generates content and a different model checks it, fabrications that would slip through single-model review are more likely to be caught.
Want to talk through how these patterns apply to what you're building? We've done this enough times to know where the edge cases are. Happy to share what we've learned.

